| 数据归一化 | 您所在的位置:网站首页 › min max规范化 › 数据归一化 |
数据归一化
|
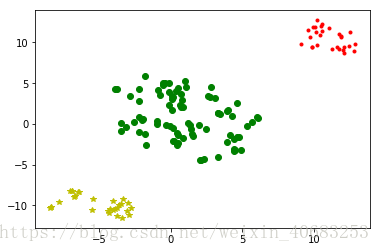
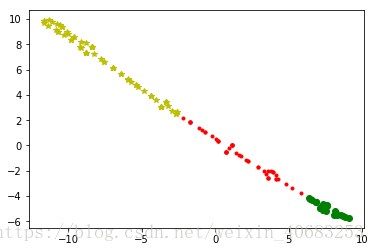
目录 归一化 数据归一化的背景介绍 MinMaxScaler:归一到 [ 0,1 ] MaxAbsScaler:归一到 [ -1,1 ] 标准化 去均值,方差规模化 归一化 数据归一化的背景介绍在之前做聚类分析的时候我们发现,聚类的效果往往特别受其中一列数据的影响,使得原本应该散布在二维平面图上的点,变成聚集在一条线上的点,可想而知,其聚类效果肯定不理想。 左图:为所有数据都归一化之后的聚类分析散点图; 右图:为其中一列是合同金额,并且没有归一化数据的散点图; 归一化方法有两种形式,一种是把数变为(0,1)之间的小数,一种是把有量纲表达式变为无量纲表达式,成为纯量。后者常见于微波之中,也就是电路分析、信号系统、电磁波传输等,研究物理的人会比较熟悉。而像我们这些普通的数据分析师的日常工作中,不太会遇见需要归一化为无量纲表达式的情况,因此只讨论归一化到 [0,1] 的情况。 归一化一般是把数据映射到 [ 0,1 ] ,但也有归一到 [ -1,1 ] 的情况,两种情况在Python中分别可以通过MinMaxScaler 或者 MaxAbsScaler方法来实现。 MinMaxScaler:归一到 [ 0,1 ] 原理 从原理中我们注意到有一个axis=0,这表示MinMaxScaler方法默认是对每一列做这样的归一化操作,这也比较符合实际应用。 eg:将数据归一到 [ 0,1 ] from sklearn import preprocessing import numpy as np x = np.array([[3., -1., 2., 613.], [2., 0., 0., 232], [0., 1., -1., 113], [1., 2., -3., 489]]) min_max_scaler = preprocessing.MinMaxScaler() x_minmax = min_max_scaler.fit_transform(x) print(x_minmax)运行结果: [[1. 0. 1. 1. ] [0.66666667 0.33333333 0.6 0.238 ] [0. 0.66666667 0.4 0. ] [0.33333333 1. 0. 0.752 ]]如果有新的测试数据进来,也想做同样的转换,那么将新的测试数据添加到原数据末尾即可 from sklearn import preprocessing import pandas as pd min_max_scaler = preprocessing.MinMaxScaler() x = ([[3., -1., 2., 613.], [2., 0., 0., 232], [0., 1., -1., 113], [1., 2., -3., 489]])#原数据 y = [7., 1., -4., 987]#新的测试数据 x.append(y)#将y添加到x的末尾 print('x :\n', x) x_minmax = min_max_scaler.fit_transform(x) print('x_minmax :\n', x_minmax)运行结果: x : [[3.0, -1.0, 2.0, 613.0], [2.0, 0.0, 0.0, 232], [0.0, 1.0, -1.0, 113], [1.0, 2.0, -3.0, 489], [7.0, 1.0, -4.0, 987]] x_minmax : [[0.42857143 0. 1. 0.57208238] [0.28571429 0.33333333 0.66666667 0.13615561] [0. 0.66666667 0.5 0. ] [0.14285714 1. 0.16666667 0.43020595] [1. 0.66666667 0. 1. ]]每一列特征中的最小值变成了0,最大值变成了1. MaxAbsScaler:归一到 [ -1,1 ] 原理与MinMaxScaler相似, from sklearn import preprocessing import numpy as np x = np.array([[3., -1., 2., 613.], [2., 0., 0., 232], [0., 1., -1., 113], [1., 2., -3., 489]]) max_abs_scaler = preprocessing.MaxAbsScaler() x_train_maxsbs = max_abs_scaler.fit_transform(x) x_train_maxsbs运行结果: array([[ 1. , -0.5 , 0.66666667, 1. ], [ 0.66666667, 0. , 0. , 0.37846656], [ 0. , 0.5 , -0.33333333, 0.18433931], [ 0.33333333, 1. , -1. , 0.79771615]])如果有新的测试数据进来,和原来的表一起进行归一化: from sklearn import preprocessing import pandas as pd max_abs_scaler = preprocessing.MaxAbsScaler() x = ([[3., -1., 2., 613.], [2., 0., 0., 232], [0., 1., -1., 113], [1., 2., -3., 489]])#原数据 y = [5., 1., -4., 888]#新的测试数据 x.append(y) print('x :\n', x) x_train_maxsbs = max_abs_scaler.fit_transform(x) print('x_train_maxsbs :\n', x_train_maxsbs)运行结果: x : [[3.0, -1.0, 2.0, 613.0], [2.0, 0.0, 0.0, 232], [0.0, 1.0, -1.0, 113], [1.0, 2.0, -3.0, 489], [5.0, 1.0, -4.0, 888]] x_train_maxsbs : [[ 0.6 -0.5 0.5 0.69031532] [ 0.4 0. 0. 0.26126126] [ 0. 0.5 -0.25 0.12725225] [ 0.2 1. -0.75 0.55067568] [ 1. 0.5 -1. 1. ]]其他数据预处理方法 数据标准化 - scale() - Python代码 拉格朗日插值法补充缺失值 连续数据离散化(等宽、等频、聚类离散) 清洗你见过的各种类型的重复 |
【本文地址】
公司简介
联系我们